
基于Transformer的信贷违约预测
A proposal about using transformer to predict credit default...


摘要:随着经济的快速增长,金融投资领域持续进步,个人信用作为融资的基石,尤为重要。准确预测个人信用违约的风险在技术革新背景下变得关键。随着大数据和计算能力的提升,传统的统计方法和机器学习算法在该领域得到了广泛应用,但它们在处理复杂、高维度数据时存在一定局限性。本文探讨了利用先进的机器学习技术,尤其是Transformer模型,来预测信用违约的可能性,为信用违约预测提供了一种新的思路和方法。
关键词:信贷违约预测,Transformer模型,机器学习
1 引言
随着经济的快速增长,金融投资领域也在持续进步。个人信用作为个人融资的基石,对于推动社会经济的繁荣和完善社会信用体系至关重要。然而,在技术革新的背景下,准确预测个人信用违约的风险变得尤为关键。信贷违约不仅对客户和银行产生负面影响,还可能对整个社会的经济稳定性造成严重威胁。
当借款人未能按照贷款协议偿还贷款本金和利息时,就会发生信用违约,也称为违约风险,从而对所涉双方造成潜在的负面影响(Sarode, 2023)。信用违约预测是金融行业的一项关键任务,尤其是在在线信贷平台的兴起和信用卡普及的情况下。过去在信贷违约预测领域,常用的方法包括诸如Logit模型之类的传统统计方法和随机森林、XGBoost和Adaboost等机器学习算法来开发准确的预测模型(José et al., 2023; Yanhua et al., 2023; Muhamad et al., 2023)。传统统计方法为决策提供了透明度,帮助利益相关者了解决策过程;而机器学习算法的采用显著提高了信用违约预测的预测准确性。
在信贷违约预测领域,数据通常以表格形式存在。传统的统计方法和早期的机器学习模型在处理这类数据时有一定的效果。然而,随着深度学习的兴起,研究者们开始探索更复杂的模型,如神经网络和Transformer,以提高预测的准确性。本文将探讨Transformer在表格数据上的应用,并讨论其在信贷违约预测中的潜力。在进行更深入的探索之前,我们需要对注意力机制以及Transformer有一个更全面的了解。
1.1 Transformer模型概述
Transformer模型最初是为自然语言处理(NLP)任务设计的,它利用自注意力机制来捕捉数据中的长程依赖关系。自从其在机器翻译任务中取得突破性进展后,Transformer模型被迅速应用到各类NLP任务中。Transformer的核心优势在于其能够高效处理并行数据,并在捕捉复杂模式方面表现出色。
1.2 注意力机制
注意力机制(Attention Mechanism)是一种模仿人类视觉注意力过程的技术,最早应用于自然语言处理(NLP)领域。它通过赋予输入数据中的不同部分不同的权重,使模型能够重点关注更为重要的信息。这种机制能够在处理长序列数据时,捕捉数据中远距离依赖关系,从而提高模型的性能。
2 文献综述
2.1 信用违约预测
国外在信用违约预测领域起步较早,已经建立了较为完善的预测体系,并广泛应用于金融机构中。信用评分是其中的关键评价指标,最早研究提出根据客户特征信息进行信用评分和分类(Fisher, 1936)。后续研究进一步提出将贷款分为“好贷款”和“坏贷款”,并在此基础上评估客户信用(Durand, 1942)。国内现有的大部分研究主要集中在比较不同方法和模型之间在个人贷款违约预测上的差异,以找到最适合进行预测的模型。
预测信用违约的算法和模型众多,涵盖传统统计学方法和前沿人工智能技术。常用的模型包括逻辑回归、决策树、随机森林、神经网络、支持向量机和判别分析法等。逻辑回归模型在信用评分研究领域强调在进行判定分析时,无需对解释变量的分布施加特殊限制(Wiginton, 1980)。在信用违约领域,机器学习算法被广泛应用,得益于其能够处理大规模和高维数据,捕捉复杂的非线性关系,提高预测准确性,并实现自动化特征工程。它们具备高度的适应性和灵活性,能够有效处理缺失值和噪声数据,支持快速响应和实时更新。一些研究表明支持向量机(SVM)模型在预测性能上明显优于逻辑回归模型(Obare and Muraya, 2018; 陈为名, 2008)。也有研究表明梯度提升模型具有很强的鲁棒性和稳定性,在预测信用违约准确性方面优于决策树模型(Chopra and Bhilare, 2018)。信用评分涉及多个因素,包括个人收入、信用历史、贷款类型等,这些因素之间可能存在复杂的非线性关系。神经网络模型可以通过多层结构和激活函数有效地学习和建模这些复杂关系,从而提高信用违约预测的准确性(Odom and Sharda, 1990; Coats and Fant, 1993; 石庆炎, 2005)。
除了使用逻辑回归,Xgboost等机器学习方法来对贷款违约概率进行预测,我们还可以使用近来在自然语言处理领域非常流行的注意力机制来处理该任务。近年来,自然语言处理(NLP)领域在使用基于Transformer的语言模型(LM)来处理自由文本方面取得了显著进展。由于表格数据中包含的重要知识,研究人员正在探索如何将这些模型扩展到结构化数据上,以便在各种数据管理和NLP任务中应用。
2.2 Transformer应用于表格数据
根据相关调查,目前将注意力机制(Transformer架构)应用于表格数据的典型方式可以被归纳于图1。该架构不仅包括用于预训练表格数据神经表示的基于 Transformer 的编码器,还有 使用生成的 LM 来解决下游任务的目标模型。对于第1项,训练数据由大量表格组成,一旦学习了该语料库的表示,就可以在2中给定表及其上下文上的下游任务。这样的架构在某些方面与自然语言不同且包含的信息更加丰富(Badaro and Saeed, 2023)。
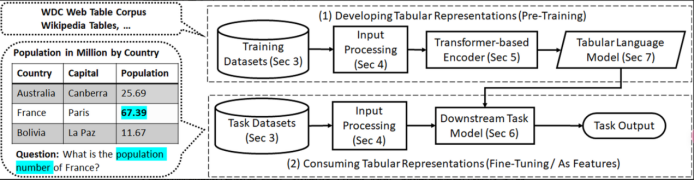
在架构中,第一步便是训练数据集。这里需要区分开用于与训练和下游任务微调的数据集。通常来收,预训练表没有注释,而用于微调的数据集具有与任务相关的注释标签。过去研究表明,为了构建大型预训练数据集并尝试减少偏差,可以使用多个来源。例如,与仅使用维基百科表进行 QA 的 TaPas (Herzig et al., 2020) 和仅使用电子表格进行 TMP 的 TabularNet (Du et al., 2021) 不同,TaBERT (Yin et al., 2020) 使用SP 的维基百科表和 WDC; GraPPa 使用 Wikipedia Tables、Spider 和 WikiSQL 作为 SP; MMR(Kostić et al., 2021)使用 NQ、OTT-QA 和 WikiSQL 进行 TR; MATE(Eisenschlos 等人,2021)使用 Wikipedia Tables 和 HybridQA 进行 QA; TUTA(Wang 等人,2021b)使用维基百科表格、WDC 和 TMP 电子表格。一般来说,建议利用不同的数据源进行预训练,以确保覆盖不同的种类和内容,从而提高表示的范围。上述工作中构建的数据集除了可应用于预训练阶段,由于其带有标签注释,同样可应用于下游任务微调阶段。具体的使用方法视情况而定。
原始数据集构建完成后,还需要进行额外的数据处理工作,由于transformer独特的架构设计,用于表格数据的transformer除了需要一系列标记作为输入,还需要进行输入数据大小的限制(Aly et al., 2021;Glass et al., 2021),二维数据转为以为数据的序列化操作(Deng et al., 2020;Yang and Zhu, 2021)以及数据和上下文的合并工作(Xie et al. ,2022)等。
Transformer架构有多种变体,包括编码器-解码器(Vaswani et al., 2017; Raffel et al., 2020)、仅编码器(Devlin et al., 2019; Liu et al., 2019)或仅解码器(Radford et al., 2019; Brown et al., 2020)模型。架构的选择取决于最终任务。仅编码器模型主要用于分类,是表格数据扩展的最流行选择。我们可以通过修改模型输入,模型内部结构,模型输出以及模型的训练程序等组件来拓展和更新标准transformer。
目前,有两种transformer结构被一定程度上证明适用于表格数据:FT-Transformer(Yury et al., 2021)以及TabTransformer(Xin et al., 2020)。两者的区别主要包括FT-Transformer 将 Transformer 数值嵌入与分类嵌入一起传递,而TabTransformer 只是将分类嵌入上下文化。另外,FT-Transformer 使用 CLS 令牌嵌入作为最后一层的输入,而 TabTransformer 则连接所有嵌入。鉴于前人在信贷违约领域使用Transformer模型的工作较少,本文后续将尝试使用TabTransformer来对信贷违约数据集进行建模与预测,并对模型训练结果进行分析。
3 研究设计
3.1 数据选择
数据来源:https://tianchi.aliyun.com/competition/entrance/531830/information
数据集包含800,000条样本和47个特征列,其中包含了用于预测的关键标签isDefault。

3.2 数据处理
首先将数据集不平衡的问题解决掉。数据集不平衡问题是指在分类问题中,不同类别的样本数量相差悬殊的情况。例如,在信贷违约预测中,违约的客户可能远少于不违约的客户,这会导致模型在训练过程中倾向于预测多数类,从而降低对少数类的预测准确性。解决数据不平衡问题后,再进行数据统计和特征工程对数据进行分析和处理。
3.2.1 解决数据集不平衡的方法
1. 重采样技术
欠采样(Under-sampling):减少多数类样本的数量,使其与少数类样本数量平衡。缺点是可能丢失有价值的信息。
过采样(Over-sampling):增加少数类样本的数量,可以通过复制现有样本或生成合成样本(如SMOTE,Synthetic Minority Over-sampling Technique)。
2. 算法调整
加权损失函数:在损失函数中引入权重,使模型在训练过程中更加重视少数类样本。例如,可以在交叉熵损失函数中为少数类样本赋予更大的权重。
特定算法设计:使用专门针对不平衡数据设计的算法,如集成方法(例如,EasyEnsemble、BalanceCascade)。
3. 数据增强
生成对抗网络(GAN):使用GAN生成少数类的合成样本,从而平衡数据集。
4. 集成学习
集成方法:结合多个模型的预测结果,以提高整体预测性能。例如,使用随机森林、梯度提升决策树等方法,通过多次采样和训练多个基学习器来提高少数类的识别能力。
5. 重新定义评估指标
在不平衡数据集上,传统的准确率指标可能不足以衡量模型性能。应该使用精确率(Precision)、召回率(Recall)、F1分数、ROC-AUC等指标,这些指标能够更好地反映模型对少数类的预测性能。
6. 数据清洗
通过数据清洗和预处理,去除或修正数据中的噪声和异常值,从而提高数据质量,减少不平衡带来的影响。
3.2.2 数据统计
在数据统计部分,首先对数据集进行了全面的了解,包括样本量和特征数量。数据集包含800,000条样本和47个特征列,其中包含了用于预测的关键标签isDefault。通过info()和describe()函数,对数据类型和基本统计量进行了初步的审视。进一步的分析集中在缺失值和唯一值的检查上,发现22个特征存在缺失值,但并没有特征的缺失率高于50%。特别地,employment_Length和n11特征的缺失率超过了0.05,而其他特征的缺失率较低。此外,识别出policyCode特征由于只包含单一值,对违约预测没有帮助,因此在后续处理中被删除。
接下来,对数据集中的类别型特征和数值型特征进行了区分,其中数值型特征进一步细分为连续型和离散型。通过value_counts()方法分析了离散型特征的分布情况,而连续型特征的分布则通过可视化方法进行了检查,以判断是否符合正态分布。此外,还关注了特征间的相关关系,包括单一变量的分布和不同类别下变量的分布差异。时间格式数据的处理也得到了特别关注,issueDateDT特征的处理显示了数据集中日期的相对位置。最后,透视图的使用帮助深入理解了数据的多维关系。
3.2.3 特征工程
在特征工程部分,首先对数据进行了预处理,包括缺失值的填充和异常值的检测与处理。对于数值型特征,采用中位数填充处理缺失值,而对于类别型特征,则根据其特性采用labelencode或one-hot编码转换为数值型。异常值的处理采用了基于均值和标准差的阈值方法,通过删除含有异常值的样本,将样本量从800,000减少至612,741。
特征交互的探索考虑了不同特征间可能的组合,以发现新的特征组合对违约预测的潜在影响。此外,还考虑了高维特征的编码问题,通过labelencode将类别型特征编码后直接用于树模型。
特征预处理的重点是归一化,以消除不同量纲和量级带来的影响,确保模型训练的稳定性和效果。特征选择阶段,通过相关性矩阵热力图分析了特征间的相关性,并采用了皮尔森相关系数法来挑选与响应变量关系最密切的特征,最终选定了20个特征用于建模。
最后,特征选择后的数据被划分为训练集和测试集,为后续的建模和调参打下了基础。通过这一系列细致的特征工程步骤,为构建一个准确预测贷款违约风险的模型提供了坚实的数据基础。
3.3 模型选择
3.3.1 算法逻辑
Tabtransformer架构的工作原理如下:
1. 所有分类特征都使用相同的 embedding_dims 编码为嵌入。这意味着每个分类特征中的每个值都有自己的嵌入向量。
2. 列嵌入(每个分类特征一个嵌入向量)被(逐点)添加到分类特征嵌入中。
3. 嵌入的分类特征被输入到一堆 Transformer 块中。每个 Transformer 块由一个多头自注意力层和一个前馈层组成。
4. 最终 Transformer 层的输出(即分类特征的上下文嵌入)与输入数字特征连接,并馈入最终的 MLP 块。
5. softmax 分类器应用于模型末尾。
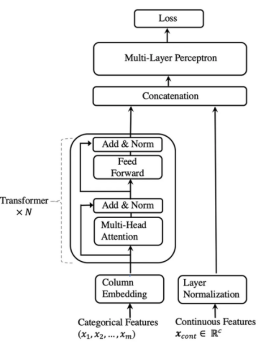
该架构的主要优点包括:
1. 捕获特征交互:自注意力机制可以学习特征之间的复杂关系。
2. 上下文嵌入:增强分类特征的表示。
3. 可扩展性:适用于具有高维特征的大型数据集。
3.3.2 模型训练
使用pytorch框架,设置训练参数,包括多头注意力数量,嵌入特征的维度数等。具体内容请参考后续tabtransformer-experiment文章。
4 研究结果
4.1 算法对比效果分析
预期的研究结果主要有以下三个部分:
TabTransformer的模型训练、验证表现(Accuracy,AUC曲线)
对比transformer与目前标准的机器学习方法逻辑回归,多层感知器,xgboost以及adaboost的结果,算法的优劣分析。最终形成表格和AUC曲线
做与不做数据处理(数据集不平衡问题)下的模型表现对比(Accuracy,AUC曲线)
4.2 各算法的优劣分析
4.2.1 TabTransformer
1. 优点:
(1) 处理高维数据的能力:TabTransformer能够有效处理包含大量特征的数据集,特别是具有复杂交互的特征。
(2) 特征嵌入:通过嵌入层将类别特征转换为高维空间中的向量,能够捕捉类别特征之间的复杂关系。
(3) Transformer结构:利用Transformer块,能够处理序列数据,捕捉远程依赖关系。
(4) 适用于表格数据,能够处理混合类型的特征(数值型和类别型)。
(5) 有潜力在处理复杂的特征交互时表现出色。
2. 缺点:
(1) 训练时间长:Transformer模型通常需要较长的训练时间,尤其是当数据集较大时。
(2) 高内存消耗:由于Transformer结构的复杂性,训练过程中的内存消耗较高。
(3) 模型复杂性:参数较多,需要更多的调参工作,容易导致过拟合或欠拟合。
3. 优化方案:
(1) 调整模型参数(如embedding维度、transformer block数等)。
(2) 进行超参数优化(如使用网格搜索或随机搜索)。
(3) 增加训练数据量或进行数据增强。
(4) 尝试不同的前处理技术(如特征选择、特征工程)。
4.2.2 Adaboost
1. 优点:
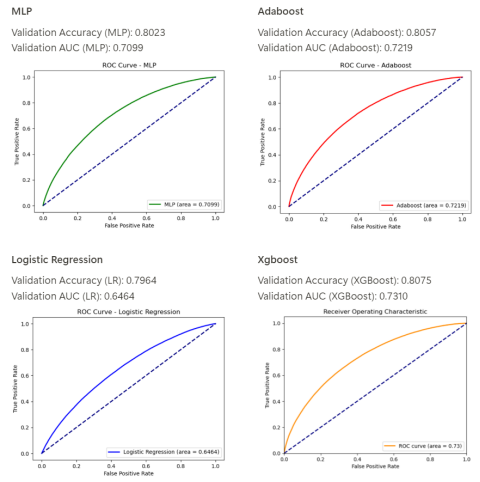
(1) 验证集AUC较高(0.7219),说明其在区分正负样本方面表现较好。
(2) 对弱分类器的增强效果显著,能够提高整体模型的性能。
(3) 容易理解和实现,适用于各种二分类问题。
2. 缺点:
(1) 对噪声数据较为敏感,可能会导致过拟合。
(2) 训练时间较长,尤其是在迭代次数较多时。
3. 优化方案:
(1) 调整弱分类器的数量(n_estimators)和学习率(learning_rate)。
(2) 使用更强的基分类器(如深度决策树)代替默认的决策树桩。
(3) 进行特征选择和特征工程,以减少噪声和冗余特征。
4.2.3 Logistic Regression
1. 优点:
(1) 模型简单,计算成本低,易于实现和解释。
(2) 对高维稀疏数据有较好的处理能力。
(3) AUC较高(0.6464),说明其在区分正负样本方面有一定的表现。
2. 缺点:
(1) 对非线性可分数据效果较差,无法捕捉复杂的特征关系。
(2) 需要进行特征缩放和特征选择,才能达到较好的效果。
3. 优化方案:
(1) 添加多项式特征或交互特征,以提高模型的非线性能力。
(2) 进行特征选择和特征工程,去除冗余和无关特征。
(3) 调整正则化参数(如L1或L2正则化),以防止过拟合。
4.2.4 XGBoost
1. 优点:
(1) 验证集AUC最高(0.7310),说明其在区分正负样本方面表现最佳。
(2) 对处理缺失值和不平衡数据有较好的效果。
(3) 具有内置的正则化机制,能够防止过拟合。
(4) 支持并行计算和分布式计算,训练速度快。
2. 缺点:
(1) 模型复杂,调参较为繁琐。
(2) 训练时间较长,尤其是在数据量较大时。
3. 优化方案:
(1) 进行超参数优化(如使用网格搜索或贝叶斯优化)。
(2) 调整树的深度(max_depth)、学习率(eta)和子采样比例(subsample)。
(3) 进行特征选择和特征工程,以减少模型复杂度和训练时间。
4.2.5 MLP(多层感知器)
1. 优点:
(1) 具有捕捉复杂非线性关系的能力,适用于多种复杂的分类问题。
(2) 验证集AUC为0.7099,显示其在区分正负样本方面有较好的表现。
2. 缺点:
(1) 训练时间较长,特别是在深度网络或大规模数据集上。
(2) 对超参数(如隐藏层数量、神经元数量、激活函数等)敏感,需要调参。
3. 优化方案:
(1) 进行超参数优化,例如使用网格搜索或随机搜索。
(2) 使用正则化技术(如L2正则化、dropout)来防止过拟合。
(3) 调整网络架构(如增加或减少层数、调整神经元数量)。
5 结论
本文研究了Transformer模型在信用违约预测中的应用,借鉴了最近火热的注意力机制,,尝试从数据中挖掘出更多的特征信息。通过实验验证了其在处理高维、复杂特征数据时的优越性能。相比传统的机器学习算法,Transformer模型在捕捉特征之间复杂关系方面表现突出,具有更高的预测准确性和处理复杂特征交互的能力。然而,Transformer模型也存在训练时间长、内存消耗高、模型复杂等缺点。未来的研究可以通过优化模型参数、增加训练数据量及应用不同的前处理技术来进一步提升模型性能。
参考文献
[1] Aly, R., Guo, Z., Schlichtkrull, M. S., Thorne, J., Vlachos, A., Christodoulopoulos, C., Cocarascu, O., & Mittal, A. (2021). FEVEROUS: Fact extraction and VERification over unstructured and structured information. In Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 1). https://doi.org/10.18653/v1/2021.fever-1.1
[2] Badaro, G., Saeed, M., & Papotti, P. (2023). Transformers for tabular data representation: A survey of models and applications. Transactions of the Association for Computational Linguistics, 11, 227-249.
[3] Bhagavatula, C. S., Noraset, T., & Downey, D. (2015). TabEL: Entity linking in web tables. In International Semantic Web Conference, pages 425–441. Springer. https://doi.org/10.1007/978-3-319-25007-6_25
[4] Brown, T. B., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., Agarwal, S., Herbert-Voss, A., Krueger, G., Henighan, T., Child, R., Ramesh, A., Ziegler, D. M., Wu, J., Winter, C., Hesse, C., Chen, M., Sigler, E., Litwin, M., Gray, S., Chess, B., Clark, J., Berner, C., McCandlish, S., Radford, A., Sutskever, I., & Amodei, D. (2020). Language models are few-shot learners. CoRR, abs/2005.14165.
[5] Chopra, A., & Bhilare, P. (2018). Application of ensemble models in credit scoring models. Business Perspectives and Research, 6(2), 129-141.
[6] Coats, P. K., & Fant, L. F. (1993). Recognizing financial distress patterns using a neural network tool. Financial management, 142-155.
[7] Deng, X., Sun, H., Lees, A., Wu, Y., & Yu, C. (2020). TURL: Table understanding through representation learning. Proceedings of the VLDB Endowment, 14(3):307–319. https://doi.org/10.14778/3430915.3430921
[8] Devlin, J., Chang, M.-W., Lee, K., & Toutanova, K. (2019). BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 4171–4186, Minneapolis, Minnesota. Association for Computational Linguistics.
[9] Durand, D. (1941). Risk elements in consumer instalment financing. Nber Books.
[10] Du, L., Gao, F., Chen, X., Jia, R., Wang, J., Zhang, J., Han, S., & Zhang, D. (2021). TabularNet: A neural network architecture for understanding semantic structures of tabular data. In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, pages 322–331. https://doi.org/10.1145/3447548.3467228
[11] Eisenschlos, J., Gor, M., Mueller, T., & Cohen, W. (2021). MATE: Multi-view attention for table transformer efficiency. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 7606–7619. https://doi.org/10.18653/v1/2021.emnlp-main.600
[12] Fisher, R. A. (1936). The use of multiple measurements in taxonomic problems. Annals of eugenics, 7(2), 179-188.
[13] Glass, M., Canim, M., Gliozzo, A., Chemmengath, S., Kumar, V., Chakravarti, R., Sil, A., Pan, F., Bharadwaj, S., & Fauceglia, N. R. (2021). Capturing row and column semantics in transformer based question answering over tables. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 1212–1224. https://doi.org/10.18653/v1/2021.naacl-main.96
[14] Gorishniy, Y., Rubachev, I., Khrulkov, V., & Babenko, A. (2021). Revisiting deep learning models for tabular data. Advances in Neural Information Processing Systems, 34, 18932-18943.
[15] Herzig, J., Nowak, P. K., Mueller, T., Piccinno, F., & Eisenschlos, J. (2020). TaPas: Weakly supervised table parsing via pre-training. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 4320–4333. https://doi.org/10.18653/v1/2020.acl-main.398
[16] Huang, X., Khetan, A., Cvitkovic, M., & Karnin, Z. (2020). Tabtransformer: Tabular data modeling using contextual embeddings. arXiv preprint arXiv:2012.06678.
[17] José, A. N., Mora, P., & Madrazo-Lemarroy, P. (2023). Loan Default Prediction: A Complete Revision of LendingClub. Revista mexicana de economía y finanzas, doi: 10.21919/remef.v18i3.886
[18] Kostić, B., Risch, J., & Möller, T. (2021). Multi-modal retrieval of tables and texts using tri-encoder models. In Proceedings of the 3rd Workshop on Machine Reading for Question Answering, pages 82–91, Punta Cana, Dominican Republic. Association for Computational Linguistics. https://doi.org/10.18653/v1/2021.mrqa-1.8
[19] Liu, Y., Ott, M., Goyal, N., Du, J., Joshi, M., Chen, D., Levy, O., Lewis, M., Zettlemoyer, L., & Stoyanov, V. (2019). RoBERTa: A robustly optimized BERT pretraining approach. CoRR, abs/1907.11692.
[20] Muhamad, A. A., Saleh, J., & Saqib, M. (2023). Improving Credit Risk Assessment through Deep Learning-based Consumer Loan Default Prediction Model. International Journal of Finance & Banking Studies, doi: 10.20525/ijfbs.v12i1.2579.
[21] Odom, M. D., & Sharda, R. (1990, June). A neural network model for bankruptcy prediction. In 1990 IJCNN International Joint Conference on neural networks (pp. 163-168). IEEE.
[22] O, Dm., & M, Mm. (2018). Comparison of Accuracy of Support Vector Machine Model and Logistic Regression Model in Predicting Individual Loan Defaults. Am. J. Appl. Math. Stat, 6(6), 266-271.
[23] Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., & Sutskever, I. (2019). Language models are unsupervised multitask learners. OpenAI blog, 1(8):9.
[24] Raffel, C., Shazeer, N., Roberts, A., Lee, K., Narang, S., Matena, M., Zhou, Y., Li, W., & Liu, P. J. (2020). Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of Machine Learning Research, 21:1–67.
[25] Sarode, S. (2023). Credit risk assessment using default models: a review. doi: 10.31219/osf.io/ksb8n.
[26] Sekhar, S. P. A., Verma, S., Madhavan, V., & Persad, A. (2024, February). Unveiling the power of self-attention for shipping cost prediction: The rate card transformer. In Asian Conference on Machine Learning (pp. 1263-1275). PMLR.
[27] Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, Ł., & Polosukhin, I. (2017). Attention is all you need. In Advances in Neural Information Processing Systems, volume 30. Curran Associates, Inc.
[28] Wang, Z., Dong, H., Jia, R., Li, J., Fu, Z., Han, S., & Zhang, D. (2021). TUTA: Tree-based transformers for generally structured table pre-training. In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, pages 1780–1790. https://doi.org/10.1145/3447548.3467434
[29] Wiginton, J. C. (1980). A note on the comparison of logit and discriminant models of consumer credit behavior. Journal of Financial and Quantitative Analysis, 15(3), 757-770.
[30] Xie, T., Wu, C. H., Shi, P., Zhong, R., Scholak, T., Yasunaga, M., Wu, C., Zhong, M., Yin, P., Wang, S. I., Zhong, V., Li, C., Boyle, C., Ni, A., Yao, Z., Radev, D., Xiong, C., Kong, L., Zhang, R., Smith, N. A., Zettlemoyer, L., & Yu, T. (2022). UnifiedSKG: Unifying and multi-tasking structured knowledge grounding with text-to-text language models. arXiv preprint arXiv:2201.05966v3.
[31] Yang, X., & Zhu, X. (2021). Exploring decomposition for table-based fact verification. In EMNLP, pages 1045–1052, Punta Cana, Dominican Republic. Association for Computational Linguistics. https://doi.org/10.18653/v1/2021.findings-emnlp.90
[32] Yanhua, S., Yanhui, F., & Yonghui, D. (2023). Online credit default prediction model based on fusion of Random Forest and XGBoost algorithm. doi: 10.1109/ICIBA56860.2023.10165530.
[33] Yin, P., Neubig, G., Yih, W., & Riedel, S. (2020). TaBERT: Pretraining for joint understanding of textual and tabular data. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 8413–8426, Online. Association for Computational Linguistics.
[34] Y, Sreekar, P. A., Verma, S., Madhavan, V., & Persad, A. (2024, February). Unveiling the power of self-attention for shipping cost prediction: The rate card transformer. In Asian Conference on Machine Learning (pp. 1263-1275). PMLR.
[35] 石庆焱. (2005). 一个基于神经网络——Logistic 回归的混合两阶段个人信用评分模型研究. 统计研究, (5), 45-49.
[36] 陈为民, 马超群, & 冯广波. (2008). 基于 KMOD 核函数的 SVM 方法在信用评分中的应用. 经济数学, 25(1), 24-27.
 | A guest post by
|